Let’s make a restaurant Tinder
Have you ever had to make plans with more than 2 people?

This is my publication that can be found on: https://priorart.ip.com/IPCOM/000266977
One of the common uses of memory is for control blocks. Large numbers of control blocks can be created depending on program activity and the type of control block. Control blocks vary widely. Some are small, and others are very large, but most are critically important to proper system and program operations. Invalid data in these control blocks can lead to a wide variety of random errors, including ABENDs, hangs, data integrity issues, and, in some cases, system outages that are needed to clear out invalid data.
Control blocks can be damaged through storage overlays or by program errors. In other cases, a control block may have valid data, but identifying that an area of memory holds a certain control block may aid in problem diagnosis.
The first step in diagnosing issues related to a control block with valid or invalid data is determining the identification of the area of storage as a particular control block. Some control blocks have eye catchers for identification and are externally documented. Other control blocks are not externally documented and may not have a recognizable eye catcher. An intelligent methodology is needed to identify mystery control blocks to greatly increase diagnostic efficiencies.
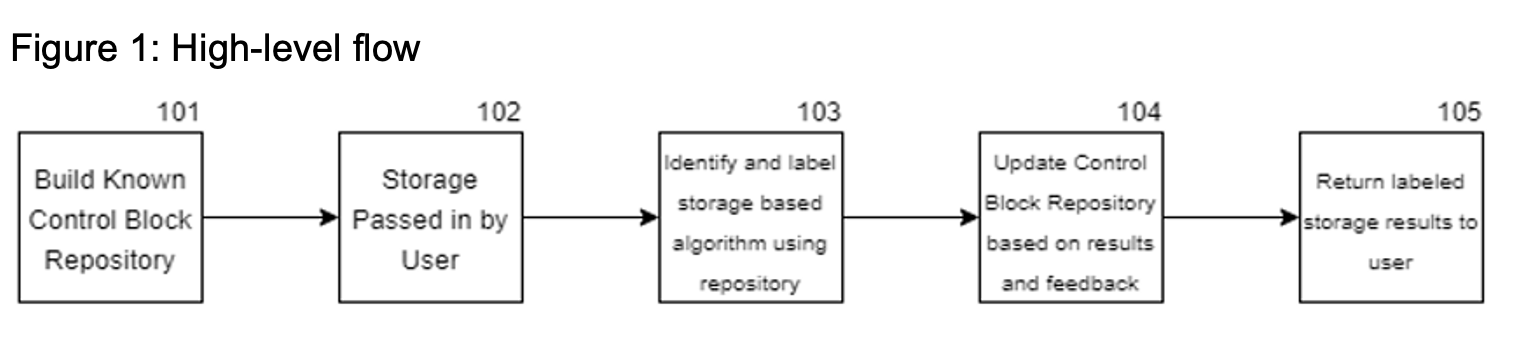
Proposed is a methodology to identify control blocks that uses several steps to assist in control block identification. The first step is building a repository of known control blocks. This repository contains the eye catcher and layout of the control block. The solution builds the data in the repository via the control block translator, which scans through macros and places the structured data in the repository. The solution uses the data in the repository to identify areas of storage that are known control blocks by matching the characteristics of the data in memory with attributes in the repository starting with the possible eye catcher value.
When the solution suspects that an area of storage is an unknown control block, the solution takes additional steps to try to identify related areas of storage referenced by that control block. Based on these associations to other known control blocks, identification of that control block may be possible. When identification is not possible, based on the types of associated control blocks, the solution provides a direction for analysis to proceed and allows experts from those other areas to assist in identification.
If the solution makes an identification, the solution updates the repository of known control blocks with the attributes of this newly identified control block so that future events will allow for identification.
The identification of the unknown control block or generation of known associations to the unknown control block is novel.
The Repository of Known Control Blocks The prerequisite step of the solution involves building a repository database of known control blocks. This database contains a mapping of control blocks by name and the expected values contained within each control block. Some of the data types contained in the control block mapping include character data (eye catchers, strings), numeric data (floats, integers), and pointers. The solution can make additional data types known to the control block repository over time.
The solution also associates metadata with the control block data types in individual mappings that indicate likely ranges or common values that have been known to appear within examples of the associated control block. For example, if all known instances of control block A have an 8-character string starting at offset +4 into the control block and the first three characters of that data area are always ABC in every known example, the solution saves this as metadata within the control block mapping. Upon observing additional examples, the solution updates the metadata.
Pointers are a special data type. Pointers link to another control block within the control block repository and are labeled with the name of said control block.
The solution initially creates the control block repository from control block listings associated with the source code of the application for which the solution will be used. The solution scans each control block listing and converts each listing into an entry in the known control block repository. After the initial load, the solution can perform additional scans to load new listings.
Developers of applications can pre-build a repository of control blocks that can be added on to an existing repository. As the algorithm utilizes a repository and new control blocks are identified based on user feedback, the solution adds these control blocks to the repository. The solution also updates the metadata of existing control blocks to increase the accuracy of the identification algorithm’s confidence.
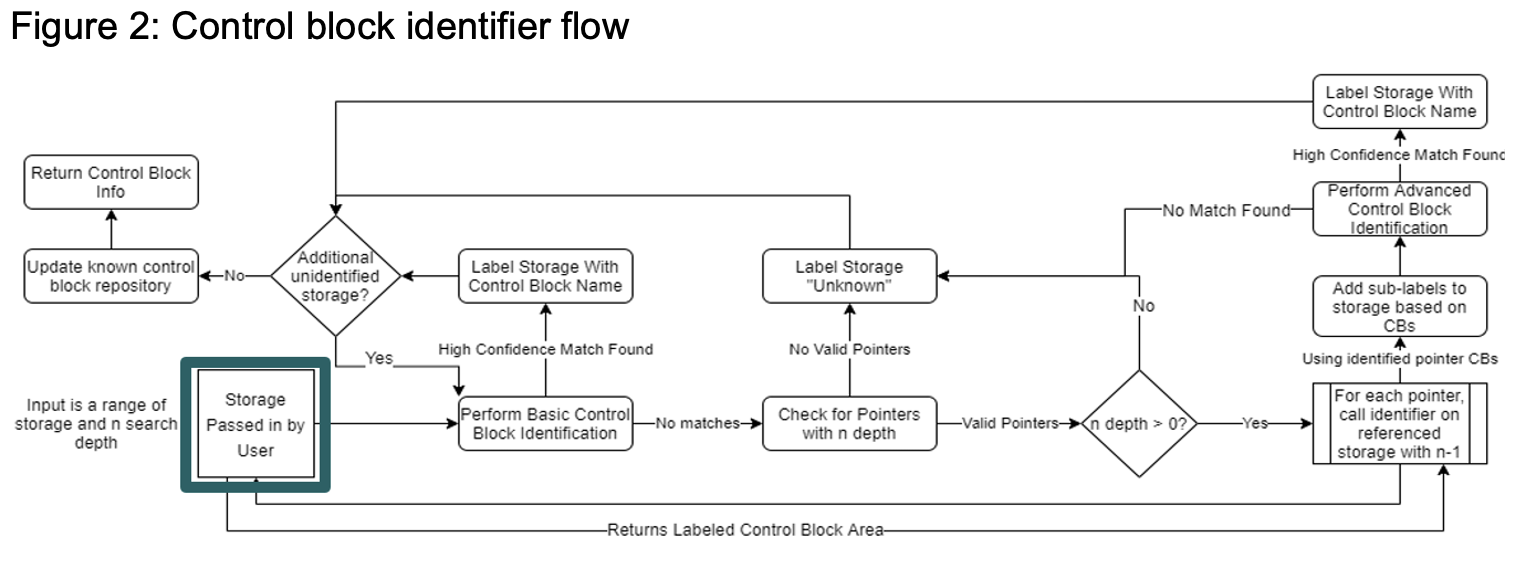
Identifying Control Blocks (High Level) The solution uses as input a range of storage to identify and the pointer search depth. The solution then labels the storage area with known control blocks and the confidence of the control block identification.
The solution has three major phases. • Phase One: The solution passes through the storage and performs a basic check on the data to detect any easily identifiable control blocks based on eye catchers and simple data types. If the solution finds a high confidence match within the database at this step, the solution labels the data and continues with any unlabeled storage. • Phase Two: This phase occurs for any storage that was not labeled under phase one. The solution identifies any pointers within the storage area and recursively calls the control block identifier on the storage pointed to by the pointers with depth n-1 until n = 0. The result of the recursive call is labeled control blocks (if identifiable). The solution associates the labeled control block names with the pointers that pointed to the blocks. The solution uses the newly labeled pointer data areas in the advanced control block identification in phase three. • Phase Three: The solution uses labeled control block data (now including labeled pointers) to perform an advanced check against the known control block repository. If the solution finds a high-probability match, the solution labels the storage with the control block name. If no match is found, the solution labels the storage as unknown. Any individual pointers that were labeled are labeled in the unknown area. If many of the labeled pointers belong to the same component area of a product, the solution labels the unknown area as unknown but associated with that product area.
After the entire passed in storage area is labeled, the solution returns the results to the user and updates the known control block repository with new metadata. In another step, the solution asks the user to provide feedback regarding the labeled output. The user can confirm that the output was labeled correctly and/or provide alternative labels for unknown control blocks. The solution feeds this data back into the control block repository for future runs.
Basic Check Details
The basic check first checks for any known character data fields at a fixed location, often referred to as an eyecatcher. For example, an XYZ control block may contain ‘XYZ’ at offset x’100’. The basic check looks for known eyecatchers and attempts to identify storage as a known data area based solely on these known eyecatchers. The more eyecatchers the check finds within the storage, the greater the confidence level the check has in determining that area of storage.
Advanced Check Details The advanced check consists of comparing the contents of the storage in question against the data types defined in the known mapping repository. For example, each byte of fields defined as character data should fall within the range of valid character encoding characters. The solution compares any fields that are required to be a specific value (e.g., 0) to determine how likely this structure is to be a match for the data type in question. When comparing a data area to known control blocks in the repository, the advanced check also considers fields that may be pointers to other control blocks.
The advanced check uses all detectable data types (including control block pointers) within a given storage area and searches the known repository for a high confidence match. The confidence of a match is a function of the number of data areas that match expected values of the control block based on the block’s mapping.
The solution can also give individual data areas within the mapping certain weights to influence the confidence level. For example, character encoding or control block pointers may have a higher confidence weight than FLOAT values when the values match. The more data areas from within the unknown control block that match a known control block, the higher the confidence value.
The advanced check also factors in specific data values when weighing the confidence of a match. For example, if a FLOAT value is known to be within a certain range in the repository, whether or not the unknown area is within that range increases/decreases the confidence factor for that data area.
Identify Pointers Details This takes place as part of the advanced check. When a value in a particular field/offset is used as a pointer, the program looks at the storage located at that location to see if identification of the storage is possible. For example, if the solution finds that the storage pointed to by offset x’2c’ is consistent with a DEF control block, the solution knows that the structure being analyzed has a DEF ptr at +x’2c’. The solution uses this information in conjunction with the other known fields to determine the most likely data area match for the input area.
The solution runs recursively on storage areas that appear to be valid pointers to attempt to identify the control block being pointed to. This results in each pointer being labeled with a control block name and degree of confidence or being labeled as unknown.
The solution factors the labeled pointers and associated confidences into the advanced check against the repository of known control blocks. Specifically, when comparing against entries in the repository, the labeled pointer increases the overall match confidence when the pointer matches the expected control block at a given offset. The amount of confidence increase is a multiple of the confidence of the pointer itself as identified in the recursive call. For example, if the solution identifies a pointer to a control block with 75% confidence, the match in the overall advanced check weight is at 75%.
Have you ever had to make plans with more than 2 people?
Code to move the rover
How to build a toy version of Shazam
Blockchain DeFi idea
Why I work on tools
This is my publication that can be found on: https://priorart.ip.com/IPCOM/000266977
The path to modernizing a legacy platform
This post is about my life!